背景
- 这篇文章是我在浏览ACL2019 list的时候发现的,感觉比较有意思 - 无监督QA。同时,为了本周的组会所准备。
资料库
- 文章链接:https://arxiv.org/abs/1906.04980
- 文章背景:《unsupervised Question Answering by Cloze Translation》是ACL 2019的长文之一,19年6月份上传到Arxiv
- 代码链接:https://github.com/facebookresearch/UnsupervisedQA
- 一个中文阅读笔记:https://blog.csdn.net/ljp1919/article/details/102475283
- 一个在此文基础上做了拓展的报告:https://medium.com/illuin/unsupervised-question-answering-4758e5f2be9b
- Facebook导读页:https://ai.facebook.com/blog/research-in-brief-unsupervised-question-answering-by-cloze-translation/
文章内容
摘要
- 本文主要做了以下两个工作:
- 探索抽取式QA在多大程度上依赖于高质量的训练数据
- 尝试探索无监督QA任务的可能性
- 为此,本文先使用无监督的方法生成(单个段落,问题,答案)三元组,然后自动合成抽取式QA数据。具体过程是从海量文档中随机抽出段落,然后随机从段落中抽取出名词短语或命名实体作为答案;再把包含答案的局部文本转换为完形填空式问题(cloze question),最后把这个完形填空式问题转写成自然语言问题。
- 上述过程中最难的是把完形填空式问题改写成自然语言问题,本文尝试了多种方案,包括非对齐自然问题语料和完形填空式问题的无监督NMT、基于规则的方法等。
- 构造完这一自动合成的数据集后,本文发现直接把流行的QA模型拿过来训练后,模型可以在人工标注好的数据集上取得不错的成果。比如在SQuAD1.0上,可以取得综合56.4 F1、命名实体类问题64.5 F1的效果,胜过早期直接在SQuAD上训练的监督模型。
概述
- 抽取式QA指的是(单个文本,问题,答案)形式的阅读理解任务。以SQuAD为代表,抽取式QA已经在精心标注的数据集上有了巨大的进步,到达甚至超越了人类的回答水平。再比如最近才发布的Natural Questions数据集,也被轻松搞定。但在真实环境下,面对没有标注数据的新领域或者新的语种,这些模型就无用武之地。
- 由此,本文总结上述挑战为无监督QA任务,并将之简化为问题生成:通过无监督的方法为文本生成精准的问答对,从而构造可供现有QA模型运行的有监督数据集。这一任务不仅能帮助QA模型实现迁移学习,而且还可以在QA模型上做数据增强、实现半监督学习。
下图介绍了基本的方法框架:1.从某个领域中抽取一个段落;2.用预训练好的工具抽取NER或者名词短语,这里预训练好的工具要用到有监督的方法,但是不需要问答对、文本搭配问题等对齐数据;3.用无监督的方法把完形填空式问题改写成自然语言问题。
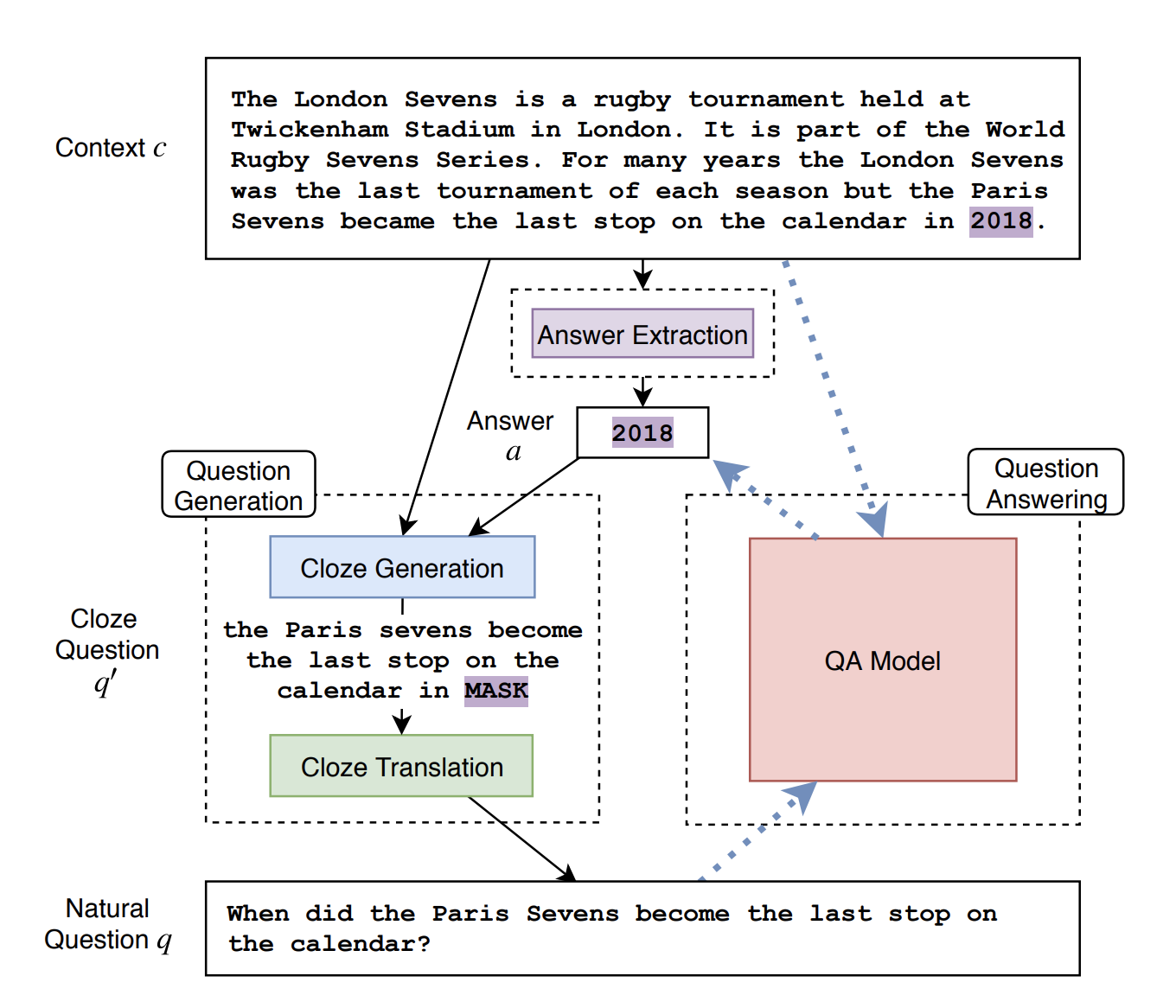
最难的部分就是改写。以往的方法是基于规则,但本文发现这种方法效果较差,而且迁移到其它领域、特别是语种时很困难。而近些年一些新的方法则需要标注数据来实现这个过程。所以,基于本文设定的任务,作者借鉴了机器翻译领域最新的无监督机器翻译方案:基于一大堆自然语言问题和另一堆非对齐的完形填空式问题,然后训练一个结合了在线回译(online back-translation)和降噪自编码(de-nosing auto-encoding)的seq2seq模型来转换两个语料。
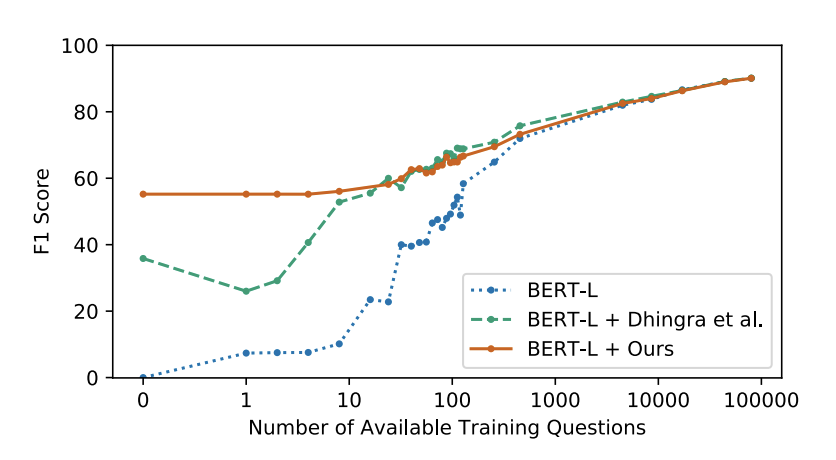
- 在实验中,本文提出的方法可以超越一些在SQuAD上的早期监督模型。同时,我们证明了在改写部分,seq2seq的方法优于词移除和词翻转的方法,词移除和词翻转又要由于传统的规则方法。此外,本文方法也非常适用于超小样本(few-shot)的启动学习:仅仅依靠32个监督样本的训练,就可以将不使用本文方法时的效果从40.0 F1提升到59.3F1。
- 总结一下,本文的贡献是:1.首次提出无监督QA任务,将之简化为无监督问题形式改写任务,并借鉴无监督机器翻译方法来完成这一任务;2.额外测试了多种问题形式改写任务的算法和假设;3.用实验证明本文方法在超小样本启动学习中的作用。
模型
- 本文的模型其实是两阶段的,第一阶段是无监督语料生成,第二阶段是适用于阅读理解的有监督判别模型。
- 第一阶段:
- 第一步:采样。随机抽一个段落,然后基于块处理(chunking)算法抽出所有名词短语,再从名词短语中抽取出NER,最后从中随机选择部分作为答案。这个过程会降低问题的多样性,但比较有用。
- 第二步:完形填空式问题的生成。直观的想法就是把答案所在的句子选出来,然后用英语语法器来进一步筛出子句以缩短问题长度。
- 第三步:问题改写,本文设计用四种方法。
- 随机或者用简单的启发规则把答案词替换成wh*疑问词
- 删除答案词,应用一个噪声函数,然后如1一样在句子头部添加一个wh*疑问词,再在句末加一个问号。这种形式的问句更贴近自然问句。其中噪声函数由词摒弃(word dropout)、词序组合(word order permutation)和词遮蔽(word masking)构成。这么做,至少针对SQuAD,能够帮助模型来学习与问题有关的n-gram重叠片段信息和提升词序变化的容错能力
- 直接使用现有的、基于规则的英文陈述句-问句转换器
- 事实上,以上方法要么需要很大的工程量或者人为制定的规则来转换,要么效果很差。所以本文用上文说的Seq2Seq来实现问题改写。详见下文
- 第二阶段:
- 一种办法是用现有的QA模型。尽管人工合成的数据质量肯定不如真实标注的,但还是寄希望于这些模型可以学到QA的pattern
- 另一种是最大化答案生成该问题的后验概率p(q|a, c),从而直接选出答案
- Seq2Seq模型的构建:
- 首先需要采集两组非对齐语料。完形填空式问题语料共计5M,从维基百科片段中随机采集得到,并用第一阶段中第二步的方法获取;当问题中的被挖去的词是NE等类型时,用5种特定类型的mask进行遮蔽,以表明答案的类型。自然语言问题语料的收集是基于一定的规则,从英文网页中爬取得到 - 这些规则包括:1.筛选出以(“how much”、“how many”、“what”、“when”、“where”和“who”)开头,并以问号结尾的句子;2.丢弃结尾为“??”、“?!”或者长度大于20个token的句子;3.去重 - 最终收集到超过100M的自然语言问题,再从中随机采样出5M作为语料(每种wh*词开头的问题数量保持相等)。
- 有了语料后就用无监督翻译模型训练,这种方法也可以被视作风格迁移任务:针对同领域的降噪自编码和针对跨领域的在线回译联合训练。
- 本文还添加了一些wh*疑问词的启发式规则。针对问题改写的前两种方法,可以根据答案类型,如Temporal来指定When的疑问词;针对Seq2Seq,则在目标问句句首添加答案类型词,比如在When句前加上“Temporal”。
- (我的解读):1.采样部分很明显是针对SQuAD这种以回答实体词为主的数据集来设计的,所以多样性低但是有用;2.第二阶段的概率模型是不是有问题,因为问句生成是基于答案上下文的,那自然用答案生成问题的后验概率会选的很准。
实验
- 实验部分主要包括本文模型的效果、本文模型与其它有监督或无监督模型的效果对比、本文模型中采用不同设计策略之间的对比、检测本文模型能否用于超小样本的训练和特别地,Seq2Seq模型能否有效生成问题。
本文模型和其它模型的效果对比:
- 在本文模型中,按上文所述有两种方法来完成第二阶段任务。对于采用现有QA模型的办法:使用finetuning BERT和BiDAF + Self-Attention;对于采用概率模型的办法:本文从句子和从句中抽取完形填空式问题,然后用UMT方法来估计最大后验概率。
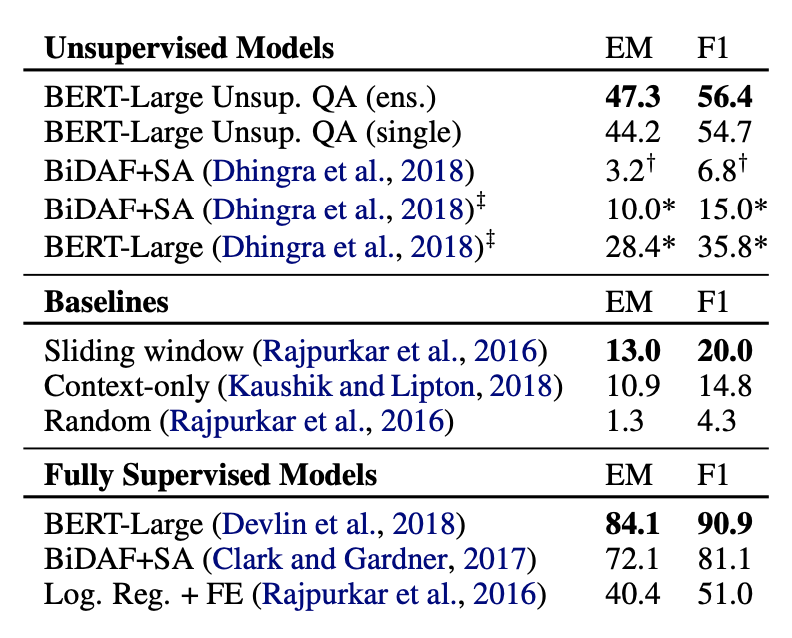
- 下图是实验结果。其中无监督的其它模型是18年Dhingra等在做半监督QA时产生的,他们也用了完形填空的思路,但是没有改写成自然问句这一步,而且严重依赖于Wikipedia文章的结构。可以看到本文模型显著高于以前的无监督方法,并且超过了SQuAD的基线有监督模型(但其实也仅仅只是高于基线模型而已)。
在SQuAD上的消融实验:测试本文模型中不同设计策略的效果对比
结果如下
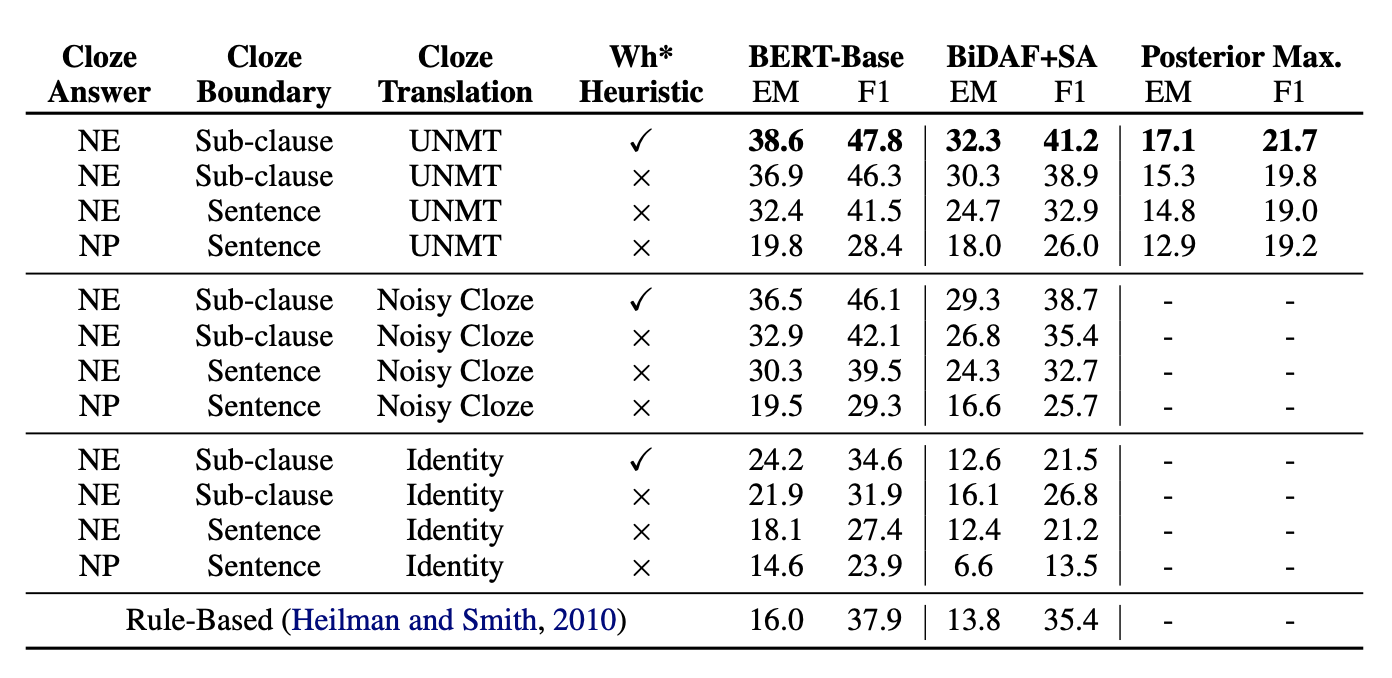
表中第一行与第二行对比,可以看出启发式规则有一定作用;第二行第三行对比,显示问句更短时效果更好;第三行与第四行对比显示用NE比NP更好,尽管在SQuAD的分析中显示NP占84.2%、NE占52.4%,但本文研究显示SQuAD中每段文本平均有33个NP14个NE,因此用NE搜索可以降低候选答案的搜索空间;第一、五、九行显示了不同问句构造方法上,Seq2Seq是最好的,但并没有第二种噪声转换的方法好很多,这说明在SQuAD上问句不一定需要非常遵循自然语序,只要让模型知道这是个问句即可。此外,从模型上也能看到用成熟的QA模型训练比用概率模型好很多。
错误分析:
- 将SQuAD dev集按照答案类型划分后,无论答案类型是不是NE,Bert为基础的无监督模型效果比较稳健(64.5 vs. 47.9),而BiDAF+SA的模型效果不稳定(58.9 vs. 23.0非NE)。这说明Bert确实已经捕捉到了一些语言学特征,而BiDAF还是更偏向于NER抽取系统。
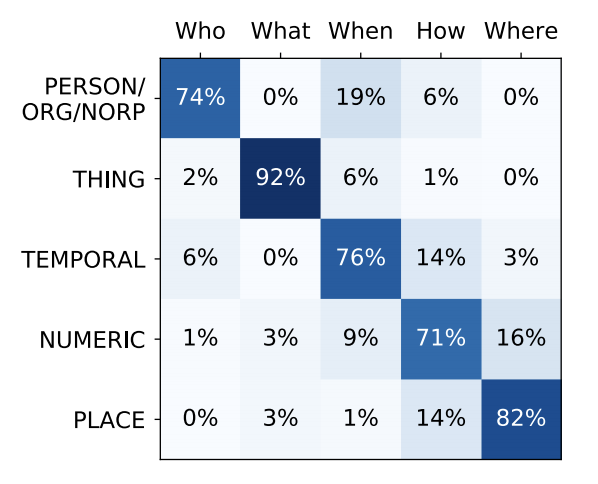
- 本文模型对于“When”类型问题处理的最好,详见论文图3。
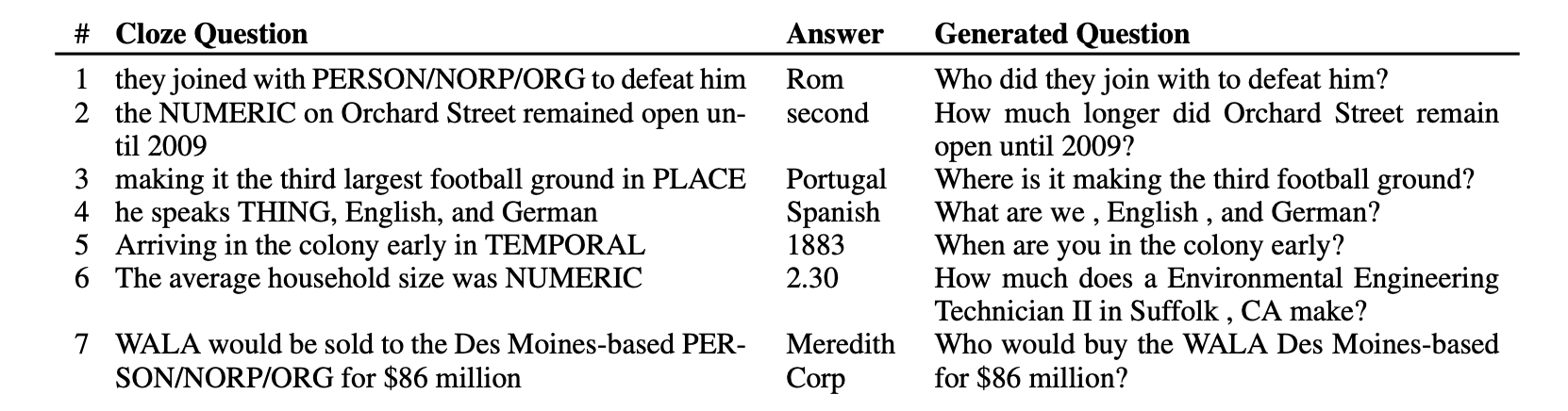
- Seq2Seq无监督翻译的具体效果分析:下图展示了一些CASE,以及具体的转换统计值。
- 超小样本的训练分析:效果非常好
我的解读
- 其实本文的思想概括起来很简单,就是用一套方法从未标注文本中生成质量低于人工标注、但成本极低的自动标注语料。然后用一些现有模型在这套语料上训练,得到一套参数后直接迁移到精心标注的语料上测试。事实证明这么做是有一定的效果的,而且能大大增加机器训练可使用的语料范围。
- 未来的改进思路可以是:1.改进问题改写/自动标注的方案;2.引入更大规模的无监督文本做实验。
- 最关键的是,这个方案在工业上会很落地。上面提到的英文复现就是一个工业界机构的成果,用XLNet能够把这个任务推到更高的SOTA。