CogQA: 针对大规模多跳阅读理解的认知图谱模型
背景
- 前几天简单了解了一下多跳阅读理解领域的重要数据集HotPotQA,接下来就开始看一些相关工作。首先梳理了一下已经公开论文的模型的时间线,可以看到研究方向的变迁:
- (1811最初探索)日本NTT的QFE模型,在Benchmark的基础上做了一点改动,区别不大
- (1902传统思路)华盛顿大学和Allen研究院的DecompQA,致力于将multi-hop问题分解成多个single-hop问题,效果一般
- (1902-05新思路GNN)清华的CogQA和KGNN、交大-字节跳动的DFGN均采用GNN来维护迭代推理网络
- (1903-05新思路优化信息抽取(Information Retrieval)环节)Technion的MUPPET旨在构建一个迭代查询的过程,检索向量会随着已经查到的线索进行更新;官方团队中的Peng Qi提出了GoldEn Retriever,这个模型旨在根据推理结果不断生成新的问题,形成一种与wiki知识库交互的查询过程;UNC提出从段落、句子和词三个层次提升信息检索的效果,在此基础上进一步进行阅读理解任务
- (1908-11思路定型)到了近几个月,从榜单来看,大家已经比较明确了两条研究思路。一是在fullwiki的设定下,必须要优化信息检索的效果来寻找正确的背景材料,二是在distractor的设定或已经找到了正确背景材料的情况下,需要实现精细化的多步推理。针对第一点,微软的HGN沿用了UNC的方案;针对第二点,京东的SAE及SAE-large、微软的HGN和哈工大-讯飞的C2F reader均继续在GNN上进行探索。这里补充一下,C2F Reader并没有出版文章,但因为是10月以来的SOTA,而且网上可以找到一点报道,所以也写进来了。
- 根据模型时间线,可以看到清华的CogQA是最早将GNN引入这一研究领域的模型,因此我也打算从CogQA开始进行论文阅读。
资料库
- 文章链接:https://arxiv.org/abs/1905.05460
- 文章背景:《Cognitive Graph for Multi-Hop Reading Comprehension at Scale》是ACL 2019的最佳DEMO Paper之一,19年5月份上传到Arxiv
- 代码链接:https://github.com/THUDM/CogQA
- 中文简介:https://zhuanlan.zhihu.com/p/72981392
文章内容
摘要
- 本文提出了一个适用于网页查询环境、可以执行多跳阅读理解的问答系统CogQA。这个系统的理论基础是认知科学中的双过程理论,实现依靠基于Bert的隐式语义抽取系统1和基于GNN的显式推理系统2。GNN网络可以清晰地展现模型推理的全路径,这是以往阅读理解模型所不具备的。CogQA在1902-05取得了HotPotQA的SOTA水平
- (我的解读):
- 首先要厘清一个概念,机器问答和阅读理解的关系。机器问答的范围比阅读理解要大,机器问答包括阅读式、生成式和检索式(可以参见我的检索式QA系统)。其中阅读式就是阅读理解。所以本文的目标就是实现一个能对给定问题进行理解,并在多个网页内容中进行推理查找,最终返回给用户答案的系统。以前的单跳阅读理解就是在一个网页中进行语义查找。在研究中,网页被简化为Wikipedia这样结构良好、内容丰富的知识文章,甚至进一步简化为其中一个段落。
- 其次关于CogQA。从概念上来说,模型很简洁;而且非常具有创新性,第一次意识到在这个问题上可以用GNN来,模拟多跳推理。
背景
- 首先本文总结了单跳阅读理解的三大缺点:
- 推理能力不足。17年针对SOTA单跳阅读理解模型的对抗性检测表明,当背景文本被刻意加上误导性信息时,模型效果会骤降。这可能是由于此前模型主要依靠语义匹配在“查找”答案,而非真正理解文本。
- 此前模型对于推理过程的解释性差。而且本文认为,HotPotQA的任务只要求给出无序的、句子级的推理依据,并不需要给出有序的、实体级的依据。在CogQA中,可以看到模型做推理的清晰过程。
- 规模不足。此前模型大部分仅在有限数据集环境下运行。为开放域问答设计的DrQA是可在大规模Wikipedia环境中运行的模型,先通过信息抽取将背景材料缩减到几个段落,再执行阅读任务。本文认为这只是一种折中,而不是真正意义上的大规模阅读理解。
- 为此本文想要从头塑造阅读理解的范式,开发一个可以解决上述问题、并适用于开放环境、多跳推理的阅读理解模型。本文借鉴了认知科学中的双过程理论:人类在认知过程中,有两个系统协同工作。系统1是隐性的、无意识的、直觉的信息检索系统,系统2是显性的、有意识的、可控的推理系统。针对HotPotQA任务,本文也构建了双系统模型CogQA,其中系统1负责抽取问题相关的实体和候选答案并输出语义表示,系统2负责推理并为系统1提供抽取线索。系统1使用Bert构建,系统2则使用GNN。
- (我的解读):这里可窥一斑的是斯坦福对于开放环境下阅读式机器问答任务的研究思路,先采用高效的信息抽取技术将开放环境缩小到相关的、有限的环境,再执行单跳、多跳等阅读理解。这一思路也影响到了后来他们提出GoldEn Retrieval这个模型,依然是把重心放在信息抽取的优化上,而其它一些机构就更关心如何在局部推理上做到最佳。所以很多机构会参加distractor赛道,而关心信息抽取的机构则会参加fullwiki赛道。但CogQA有点奇怪,它的主要工作集中在局部推理上,但却再加了一个预先信息抽取的模块后只参加了fullwiki赛道,并不能知道它在distractor赛道上的成绩。这个信息抽取的模块的误差会掩盖局部推理的提升效果。
模型结构
本文认为,可以用有向关系图G来描述人类的推理过程。G中的节点x为问题相关实体或候选答案(表现形式也是实体),推理过程就是沿着G中的边移动和计算。在模型中,系统1读取节点x的相关介绍性段落para[x]、x前序节点给出的线索(前序节点相关段落中包含x的句子),结合给定的问题,抽取出候选答案和下一跳相关实体加入到G中,并为x生成一个初始语义表示X;系统2则更新每个节点中的语义表示X进行推理计算。特别地,这种推理链可以是环形的,当某个节点x的下一跳相关实体为已经记录过的节点时,该节点依然会被加入到后续待访问节点中,这是因为新边的出现意味着新的推理线索被发现。下图是推理算法的伪代码。

文章认为这种迭代推理的策略要胜过传统信息检索,因为传统检索方案主要依靠问题语义,但多跳推理随着跳数增多,后续推理依赖的文本与问题语义关联越来越小,很难依靠传统检索方案获取。
模型实施
下图为模型结构图。
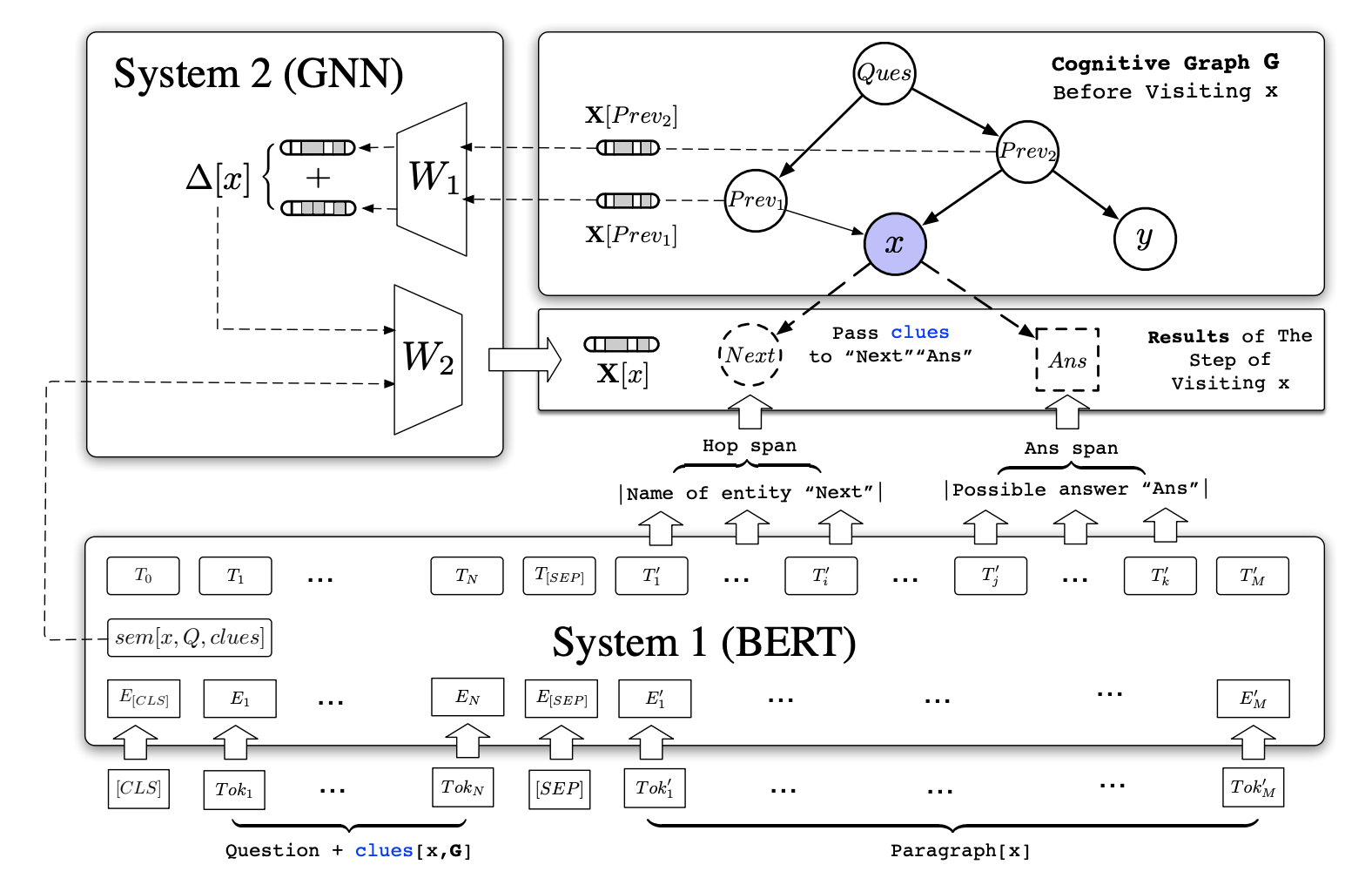
系统1:基于Bert实现,输入结构为[CLS]Question[SEP]Clues[SEQ][SEP]PARA[x]。这里会有两种特殊情况,一是对于候选答案节点,Wikipedia词条可能不存在(PARA[x]不存在),那就仅基于前面部分生成语义表示;二是初始化关系图G时,还没有Clues,那就仅使用Question和Para。如上面所述,系统1需要完成两个任务:下一步实体预测和语义表示生成。针对实体预测,模型设计两套独立的可训练参数来计算每个token作为下一跳节点和候选答案节点的起始位、终止位的概率,从而选出两个节点实体,这么做是因为下一跳节点与候选答案节点性质不同;针对语义表示生成,模型直接使用Bert倒数第三层的[CLS]表示。语义表示生成没有用最后一层表示的原因是最后一层主要负责实体预测任务,而且最后一层的[CLS]表示对应的答案起始位概率被用作鉴别当前输入的Para是否与Clues相关的负采样阈值:在TopK候选实体中,只有当实体起始位的概率大于这个阈值时,它才会被选为G中新增加的节点。
- 系统2:GNN网络。另外本文发现,GNN的更新可以留到G完全构建结束后再一次性进行,这与算法设计中的每轮更新在效果上没有大的区别,但效率上更高。
- 最终答案预测:根据疑问词可以轻易分辨出不同问题的类型,HotPotQA的数据可以分为桥梁型(可以参见我的HotPotQA阅读笔记)、一般比较型和是否型。CogQA分别使用三个全连接网络来选出候选答案节点中最可能的答案,桥梁型的输入即为迭代后的语义本身,一般比较型和是否型则输入候选答案之间的语义表示向量的差。
- 训练细节:1.起始位终止位的概率都通过数据本身来构造。答案只有一个,所以答案起始位是一个[0, 0, 1, 0, 0]这样的向量;下一跳实体可以有多个如k,那么下一跳实体起始位是一个[0, 0, 1/k, 0, 1/k]这样的向量;2.为了提高模型鉴别不相关段落的能力,作者团队提前将一些不相关的下一跳实体加入到图谱G中,由于系统1设计了负采样阈值,因此只需要将这些例子对应的起始位值直接设为1即可;3.为了提高模型鉴别正确答案的能力,也同样将一些不正确的答案实体加入到G中;4.G中还有一部分节点是正确的相关节点,这部分是通过分析训练集给的句子依据,使用基于Levenshten距离的模糊匹配实现。
- (我的解读):
- 首先有个疑问其实,一般比较型和是否型的输入是所有候选答案两两之间的语义表示向量的差吗?准备后续看代码再解决
- 负采样阈值和负样本的设计真的太棒了
实验
- 实验设置:先将系统1预训练1轮,再对系统1和2联合训练1轮
- 副产物:实验发现系统1可以单独剥离出来作为一个抽取实体的底层模块加入到别的模型中,有助于改善传统信息检索方案的效果。比如这个方法可以帮助HotPotQA的benchmark的信息检索部分,把句子依据的抽中率从56%提升到72%。
实验结果如下图。图中CogQA-onlyR指的是不做系统1预训练,直接用Benchmark中的实体初始化G;CogQA-onlyQ指的是系统1预训练时仅用问题信息;CogQA-sys1指的是仅使用系统1抽取实体。
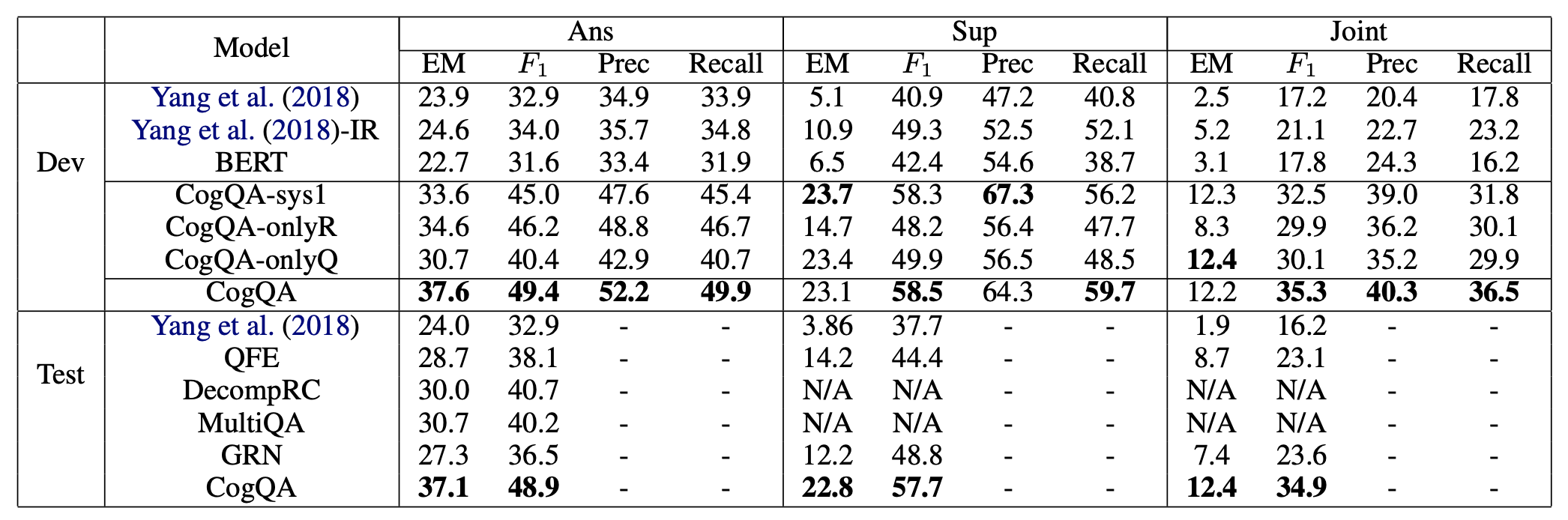
新的度量指标:logical rigor。这一指标是JointEM与AnsEM的比值,反映了数据中有多少答案是确切通过推理得到,而非语义匹配误打误撞的 。CogQA的得分为33.4%,远胜于Benchmark的7.9%。
轮次分析:下图是该指标在hop轮数上的分析,即对于模型推理能力的分析。可以看到:1.CogQA相比于Benchmark最大的特点就是推理的稳健性大大提升;2.在一般比较类和是否类问题上,CogQA并没有特别明显的效果提升,这是因为句子依据中无法推理出线索,比如问是否相等、比大小等,本文认为这部分数据需要更多的标注。
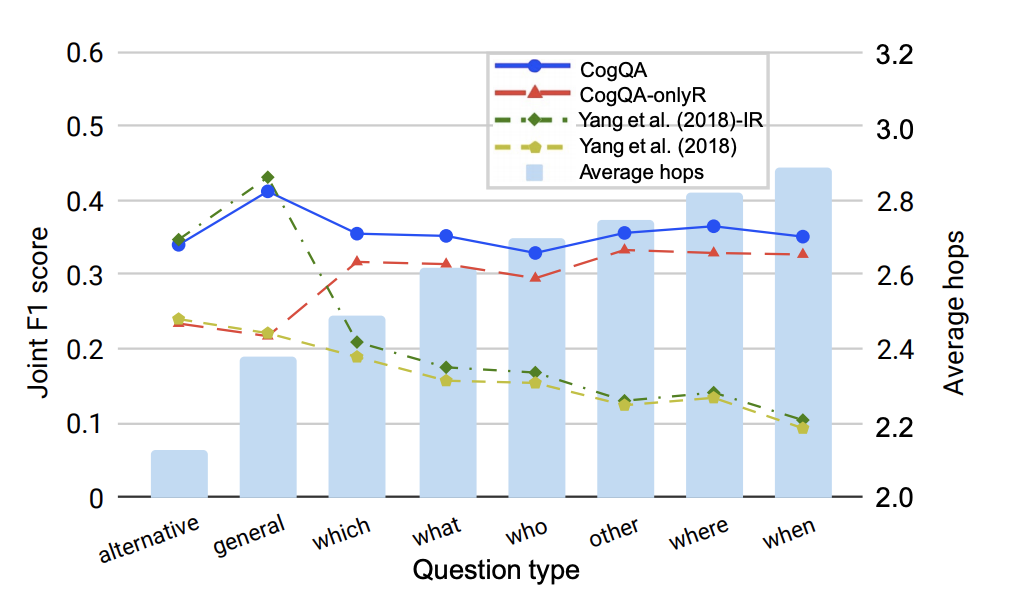
消融实验:
- CogQA-onlyR和benchmark的对比说明,CogQA优势明显
- CogQA-onlyQ的设置是为了更接近真实的人类问答:仅有问题,然后从零开始寻找资料。其效果依然说明了CogQA在信息检索和阅读推理上的优势
- CogQA-sys1的效果相比于完整的CogQA下降了很多,说明GNN推理还是很重要的
- 另外还发现系统1中Bert不是最重要的,这种语义抽取、实体查找的框架更重要
案例分析:下图展示了三个从模型预测中倒推模型如何可解释地完成多跳阅读推理的案例。Case2展示了多条推理路径的并行实现。Case3展示了迭代循环推理,分析出了笔名和真名的区别。
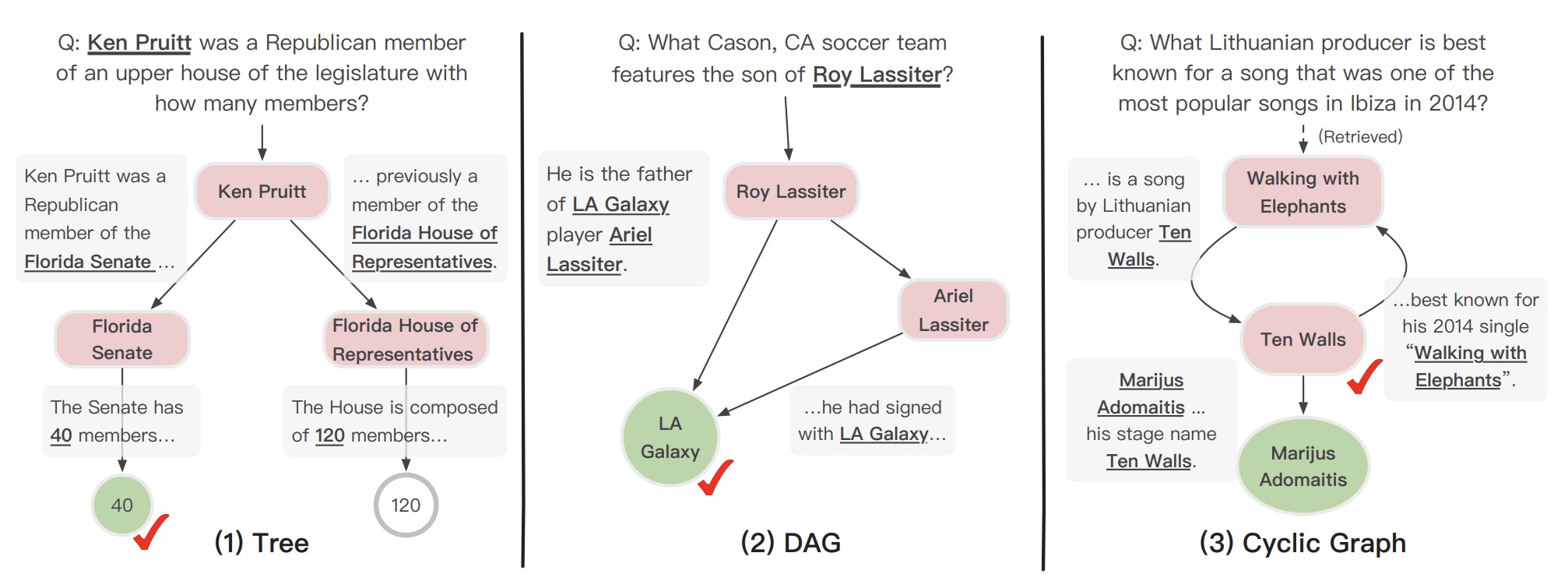
我的解读:logical rigor的提出和轮次分析比较有意思。针对没有明显提升的两类问题,可能可以通过附加模块的办法来解决 - 尽管这样做过于偏任务导向了。
我的解读
- CogQA在HotPotQA研究上是一个非常重要的模型。它用一种简洁而直观的方法实现了复杂却可解释的类人脑阅读理解机制。
- 未来的提升可能集中在三个方面,一是针对系统1构建更复杂的黑盒语义提取和实体抽取机制,二是针对系统2使用推理能力更强的图神经网络,三是针对系统1和2的交互Clues去提升其准确性。