HotPotQA: 一个旨在推动能回答开放域问题、具备高度可解释性多跳阅读理解模型研究的数据集
背景
- 最近准备开始研究前沿的阅读理解进展,目前主要想把目光放在多跳(Multi-hop)阅读理解领域。2018年6月的时候,在做本科论文的阶段,我集中讨论了当时单跳(single-hop)阅读理解的进展:依托“向量化 - 自编码 - 语义交互 - 答案抽取/生成”的框架,借助注意力机制集中提升语义交互层的语义匹配度,从而实现更准确的答案抽取或生成。18年上半年,阅读理解主要是针对(单个段落/文章,单个问题,单个回答)的任务形式。数据集代表是SQuAD(单个段落)、MS MARCO(单篇文章)以及Dureader(多篇文章)等。但这些数据针对的任务实质上都是单跳阅读理解,即从丰富的文章中抽取出答案所在的段落,然后采用(单个段落,单个问题,单个回答)的框架进行处理。Dureader可能包含了一部分需要跨文档、跨段落才能回答的问题,并且提供了同一问题下的多个回答。但从数据集设计上来看,以上数据集并没有充分考虑更贴近实际的多跳阅读理解任务。
资料库
- 文章链接:https://arxiv.org/abs/1809.09600v1
- 文章背景:《HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering》是EMNLP 2018的长文,18年9月份上传到Arxiv
- 代码链接:https://github.com/hotpotqa/hotpot
- 官网链接:https://hotpotqa.github.io/
文章内容
摘要
- 为了实现更复杂的阅读理解任务,并且鼓励可解释性很强的阅读理解模型的研究,因此文章提出了HotPotQA这一数据集。这一数据集中的绝大部分问题都需要融合多个段落的信息才能回答,即(多个段落,单个问题,单个回答)的任务形式。此外,数据集也明确给出了标注人员在回答问题时使用到的句子依据(supporting facts)。如下图所示。

背景
- 以往的阅读理解要么是单跳,要么就是伪多跳。单跳数据集上面已经讲了,伪多跳主要是指TriviaQA和SearchQA。这两个数据集虽然也是针对多跳阅读理解构建,但是基本上问题都可以通过选取单个段落来完成回答。所以其实这俩数据集和Dureader差不多。目前(2018年上半年)开始出现了确切需要多跳才能完成的阅读理解数据集,比如QAngaroo和COMPLEXWEBQUESTIONS,但它们都是基于某个知识库构建出来的,那么只要借助知识库,就比较好回答。模型在这两个数据集上实际在做的事情不是阅读理解,而是抽取知识和关系,再借助结构化的知识库做答案生成。
- 此外,没有一个数据集给出了标注人员的理解依据,也就无法学习到人的推理过程。
- 所以,提出了HotPotQA。这个数据集确保了绝大多数问题必须通过跨段落阅读来实现回答,而且给出了理解依据 - 让研究人员去想怎么让机器沿着人的推理路线去推理 - 以期实现真正的阅读理解。和上面两个多跳阅读数据集不同的是,HotPotQA不是通过现有知识库构造的,所以模型只能阅读文本去抽取/生成答案,无法依靠外界知识库。
数据集收集
- HotPotQA和SQuAD一样,都是基于维基百科的,并在亚马逊众包平台上标注实现。
- 首先,HotPotQA团队抽取了维基百科所有文章的第一段,并依据里面的超链接,构造了一个维基实体网;接着,人工选出591类维基百科上最受欢迎的查询类目,每个类中都包含了若干具体的词条(每个词条都已经选出了第一段);之后,随机选一个词条B,并根据维基实体网选一个指向该词条的邻居词条A。这就形成了两段相关的段落。最后,团队要求众包工人提一个必须借助两段段落才能回答的问题。这类构造法可称为“桥梁构造”,因为基于指向关系,标注者可以提一个从A到B,需要借助B才能回答的问题。B就是这里的“桥梁”(Bridge Entity)。
- 除了“桥梁构造”,HotPotQA团队还设计了在以往数据集中很少见到的比较类问题。他们获取了维基百科中42组相似实体的列表,按列表长度加权选出一个列表,然后随机算两个实体对应的词条作为段落。这类构造我称之为“一般比较问题”。这类问题很容易问出一个诸如“Who has played for more NBA teams, Michael Jordan or Kobe Bryant?”的问题。
- 但是比较问题中会有一类特殊情况,也就是“yes/no是否问题“。比如“Is Iron Maiden or AC/DC from the UK?”,因为是选择问题,所以完全可以依据一篇文章直接作出答案。所以在这里有个特殊规定,就是要用“Are Iron Maiden and AC/DC from the UK?”来保证多跳。
- 最后用随机法来构造候选段落对:随机数小于0.75,桥梁构造;大于0.75,且二次随机数小于0.5,构造是否问题;大于0.75,且二次随机数大于0.5,构造一般比较问题。同时,再一次指出,标注员对两个段落提出的问题回答时,会要求给出依据。
- (我的解读):从数据集构造可以看出,候选段落的构造很精妙,特意选择了容易提出多跳问题的段落对。但这一点可能会限制问题类型,也能看到从实体查找、共指消解出发去构造推理系统会是一个好的办法。另外,由于问题不是来自真实问答社区、论坛等,抽象型、概念型问题少。
数据集处理
- 经过亚马逊平台的标注,该团队总共收集到了112779个有效的样本。
这些样本经过以下步骤进行了校验与划分:
- 贡献最大(top-contributing)的标注员们标注了70%以上的数据,从中随机筛选标注样本(人均3~10条),并将这部分样本中基本仅靠单跳推理就能完成的样本归类为train-easy数据集
- 对剩下的全部数据,使用SOTA单跳推理模型进行试验,60%可被回答正确(注意:当时还没有bert,单跳推理系统的效果还没有被推到人类以上的水平)。这些被回答正确的样本归类为train-medium数据集。
- 对于最后这部分无法被当前单跳系统解决的数据,是真正的多跳阅读理解训练样本。研究团队将它拆分为train-hard、dev、test-distractor和test-fullwiki四个部分。其中,test-distractor是针对distractor条件的设计。在该条件下,团队采用bigram tf-idf的办法、将问题作为查询依据从维基百科中抽取8个段落,再加上真正相关的两个段落,模型被要求基于这10个段落,回答问题。而test-fullwiki的设计是让模型基于所有维基百科文章的第一段来回答问题。之所以要拆解出两个test集,是为了避免信息的相互流通(avoid leaking information)。
- 最后,真正的train集还是采用了三个train结合的办法。一方面是因为基准模型显示这样效果更好,另一方面是因为在数量最庞大的train-medium上,加了distractor和fullwiki的要求后,现有单跳模型效果不佳,证明这部分数据也还是具有挑战性。
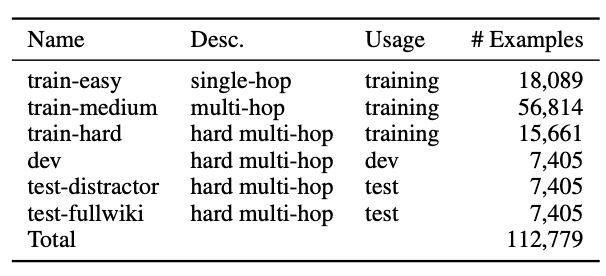
(我的解读):在直接给出两个标注段和问题的情况下,单跳推理其实在很大程度上可以回答这个数据集里的数据,按文章所说至少66%。而且自从18年12月有了Bert以后,这个准确率还可以更高。另外,train-hard、dev和两个test集才是真正的多跳样本,而且distractor和fullwiki的技术要求会有所不同。distractor是需要先从有限噪音中选出正确的段落,再采用多跳推理,在一定程度上可以参考MS MARCO和Dureader数据集;fullwiki则需要模型能够真正理解问题内容,然后再选出正确段落,再做推理。distractor还有可能继续沿用语义匹配的办法,但想在fullwiki条件下用语义匹配,那么训练成本就会大大增加。实体匹配应该是fullwiki条件下需要融合到阅读理解中的重要一步。
数据集分析
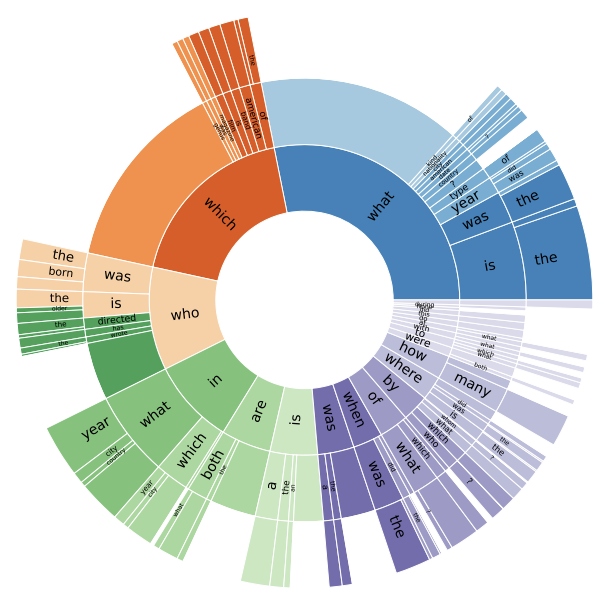
问题类型:在问题前三个词或最后一个词中查找WH-words、copulas(“is”,“are”)和auxiliary verb(“does”,“did”)作为问题中心词(CQW),然后向右扩展至多两个词或者向左扩展一个词(“in which”或“by whom”时)作为问句类型的定义。最终问题分布如下,无颜色区域是因为这种类型问题太少。
答案类型:从整个数据集中随机抽取了100个答案,68%都是回答实体,17%回答时间、数字等属性,4%回答形容词。
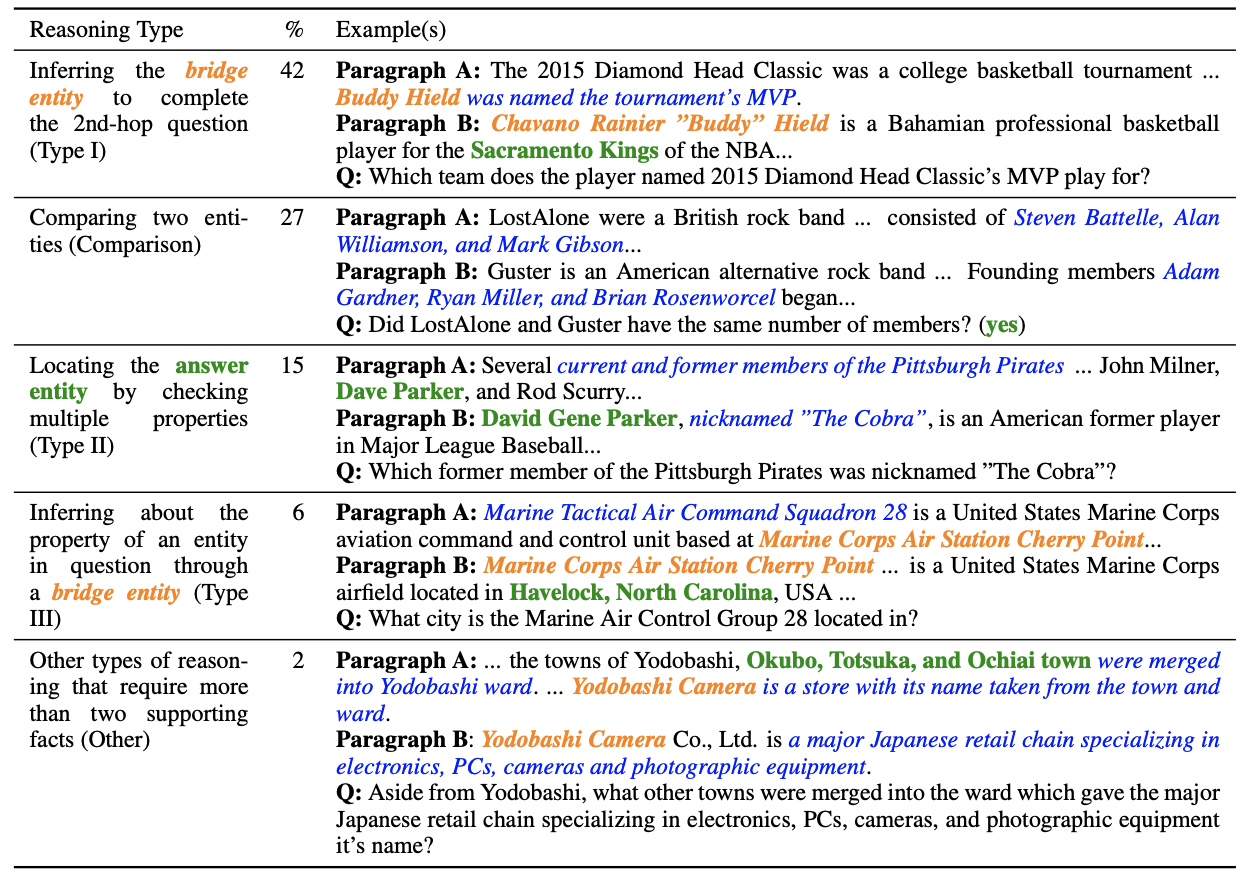
推理类型:从dev和test中随机抽取了100个样本,然后将多跳推理类型分为三类。
- 一是回答桥梁构造的推理,在问题中找到实体A,然后找到实体A的段落,从段落中分析出实体B,再到实体B所在的段落中分析出问题问的内容,这类样本占到42%。在有些情况下(6%),桥梁构造会变得简单一些,问题会有一些词能够帮助直接在实体B所在段落中定位出答案,而不需要再进行一次推理。还有一些桥梁构造推理的情况(15%),尽管不一定能直接定位答案,但问题已经暗示了足够强的属性,可以有效缩小候选实体B和答案的范围。从下表的例子可以看到,I类桥梁构造问题最难,因为可能需要背景知识或者再度推理才能知道“Sacramento King”是一个“team”;II类问题已经暗示了需要寻找former的人名,并且在这个例子中其实提供了nicknamed信息;III类问题则是通过located分析出“Havelock”是一个“city”,不像I类那样那么摸不着头脑。
- 二是回答比较类问题(27%),思路就是把问题中要比较的两个实体所在的段落都选出来,然后分析要比较的内容,比如数字、日期、年纪、国籍等。
三是其余类型:2%需要较多文中信息支撑的桥梁构造问题,6%单跳问题和2%无法回答的问题。
HotPotQA团队也在train-medium和train-hard集中做了随机100样本的推理类型分析,结果是桥梁构造类(38%+29%+2%=69%),比较类20%,其它(7%+2%+2%=11%)。总的来说类型分布还是比较一致的。
- (我的解读):首先我觉得问题类型的分析很有意思,定位问题词+扩张的方法有效区分了问题类型,这对于模型设计有很大帮助,而且这种思路在别的数据集分析上也可以用到。答案分析告诉我们这个数据基本是都是实体问题。推理类型的分析是最重要的,这说明可以从两个角度去构建模型,一是根据问题中的实体和支撑信息去寻找可能的候选段落,广度查找两次,然后结合问题中的标志词提取出答案;二是统计比较类问题的常见模板,然后依据模版进行回答。这种推理思路的分析,是对人类阅读习惯的一种分析和模仿。
实验
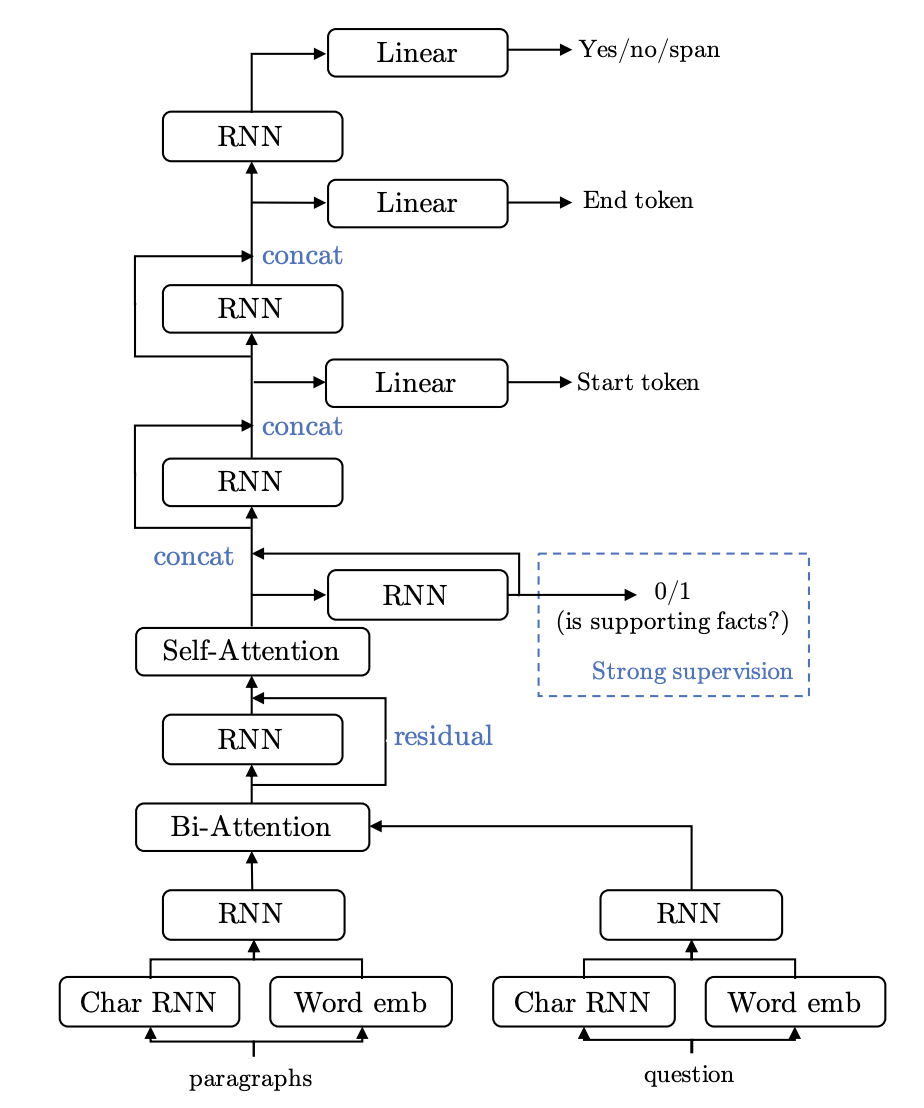
该团队基于当时最新的机器阅读理解技术 - 字符级embedding、self-attention和bi-attention - 来设计SOTA级别的基线模型。与一般针对(单个文档,单个问题,单个回答)任务的单跳阅读理解模型不同的是,他们的模型还融合了本数据集特有的句子依据。注意,他们使用一个独立的二分类器来判断任意一句句子是否是可用的依据。
训练、调试和测试设计:在进行训练前,针对fullwiki这个设定,该团队先做了信息抽取预处理,使用逆序过滤(inverted-index-based filtering)和bigram tf-idf技术选出top10段落作为候选段落。注意,这里的bigram tf-idf技术同之前构造distractor条件是一致的,top10这个数量也是为了和distractor条件保持一致。然后针对训练,因为fullwiki设定下是没有段落信息可训练的,因此训练只能基于distractor设定,然后再把训练好的模型分别应用到distractor和刚才处理过的fullwiki上进行调试和测试。
度量指标:两种指标三个维度。两种指标指的是使用EM(Exact Match)和F1。三个维度指分别在答案、句子依据和二者联合的维度上进行评估。需要特别指出,联合指标比前两个单独维度更严格。joint EM仅在答案判断和句子依据判断都正确是才为1,否则均为0。joint F1中的准确率和召回率均是两个单独维度下准确率之积与召回率之积。
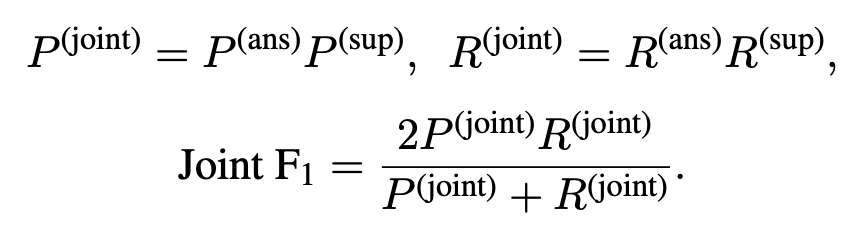
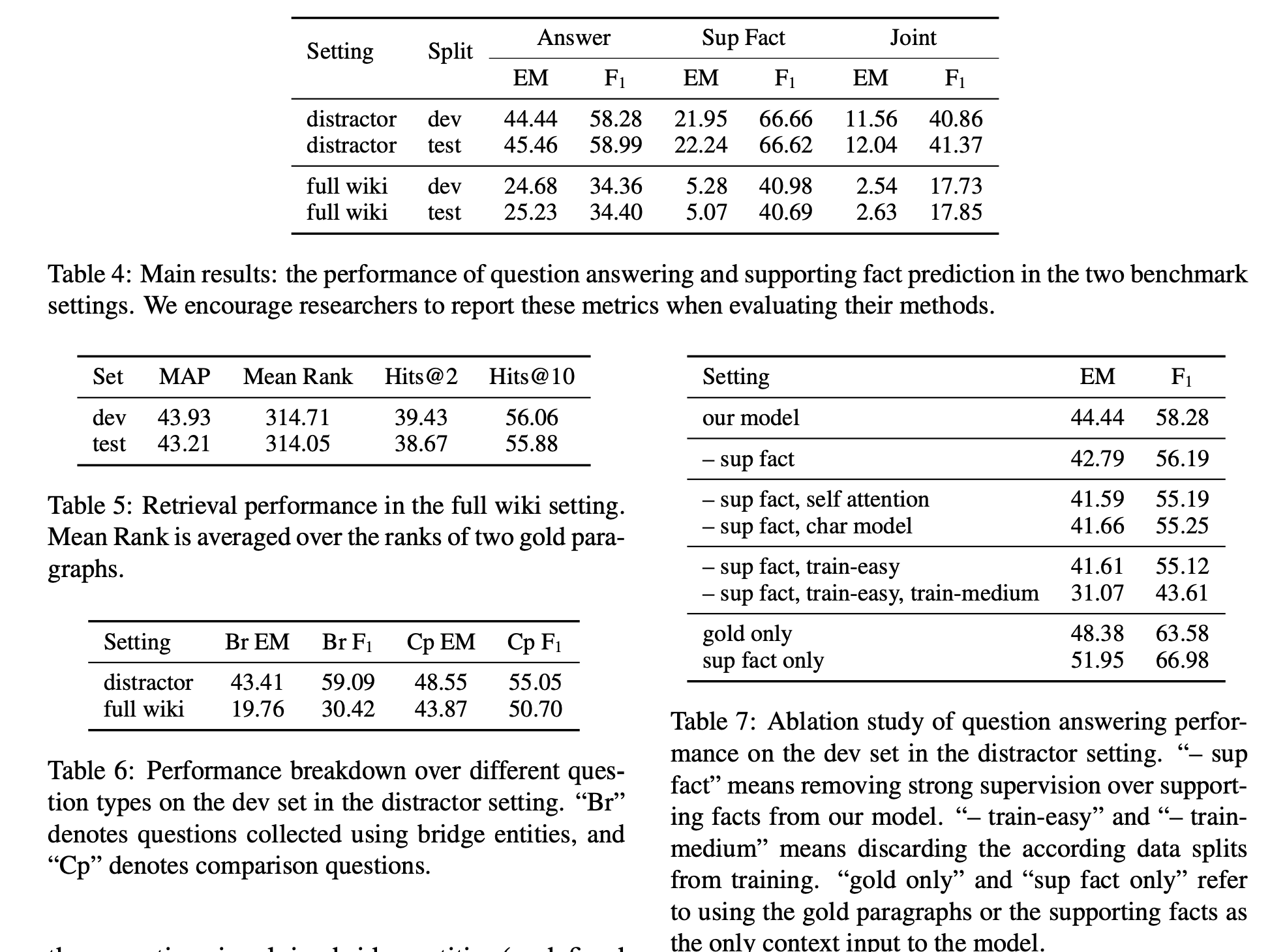
模型结果展示:一大堆表格来袭…仔细分析数字会发现:1.Table 4说明了如果不事先给出背景段落 - 哪怕是带有噪音的小范围信息 - 仅仅依靠信息检索的方法从海量wiki中检索到可能的段落,再基于检索结果进行阅读理解,效果会明显下降;2.Table 5也显示了当前检索效果一般;3.Table 6说明了检索效果不佳是由于桥梁构造类问题,而比较类问题的实体由于通常直接在问题中点明,所以查询效果较好;4.Table 7是一组消融实验,这里证明了在对正确段落加了噪音设计后(distractor)train-medium和train-easy也适合作为训练集的一部分来提高模型的效果。
人类结果测试:HotPotQA团队还额外找了一组标注人员,来测试人类在该数据集上的水平。结果证明当直接给出正确段落时,模型和人类找句子依据的能力差不多,但提取答案时模型明显不足。而当给定distractor设定时,模型就远远落后于人类。
(我的解读):这个模型是一个多任务联合的训练模型,但图画的不太好,感觉不直观(也许看了代码之后会有改观)。从结果来看,海量wiki中抽取出正确的背景段落是很难的,这可能是因为多跳之后需要参考的文本已经和问题语义关系不大。这就要求模型要能依据每一段正确的背景文本,找出完整的推理链,而这都是以前单跳模型最大的限制。
我的解读
- 整篇文章看下来,特别出彩的部分是对标注完的数据进行分析,当发现很大部分可以用单跳模型解决时,准确分析了解决的原因,并提出用添加噪音的方法去提升这部分数据的价值。最后整个数据的设计确实会引导模型开发摆脱当前(2018.06)语义匹配的导向,而转向推理链构建的导向。
补充
- CoQA和QuAC是同时期提出的另外两个阅读理解数据集,针对(单个段落,历史问答对1~n,当前问答对)的对话式阅读理解任务。这两类数据集都是在此前纯阅读理解的基础上尝试引入更贴近人类真实阅读的场景,引导模型开发从黑盒走向白盒、从语义匹配走向逻辑推理。