秋季学期的Applied Data Science课程要求做一个和城市数据有关的期末项目。我们小组设计了一个非常有哲学含义的项目:Does money make people happy?
思考
- 这是一个立意比较高、实践难度比较大的项目
- 为什么这么说?首先我们把这个命题翻译成机器学习用语就是:以能够描述金钱的变量作为特征,以能够描述人们心里高兴程度的变量为目标值,通过相关性分析或机器学习模型,能否发现这些特征与目标值之间的一定关系?
- 那么问题来了,什么变量可以描述金钱?什么变量可以描述人们心里的高兴程度呢?
思路
- 特征值:我们认为包含在人口普查数据中的一系列经济社会数据可以描述金钱,或者说可支配收入水平。此外,我们也思考是否可以扩大“金钱”这个词的内涵,比如如果一个人住在地段比较好、房价比较贵的地方,周边服务设施多,那么可能ta的心情就会比较好,又比如一个人住的房子很大、很新,那么可能ta的心情就会更好。因此结合数据可获得的难易程度,我们选取了两组数据作为特征。一是全部540+的美国人口普查经济指标,其中包含每个统计区的平均收入、平均寿命预期等等可能的因变量;二是每个统计区的中位数收入、平均房价和地价。这里的统计区是以邮编划分的。
- 目标值:自然语言处理里有一门技术叫情感分析,主要思想是利用基于大规模统计的情感词典来量化文本所体现的情绪。比如对于“今天天气真好!”这样一句话,可能量化为(正面:0.9,中性:0.2,负面:-0.1)的情感得分。至此,我们只需要寻找能够反映人们情绪的载体–大规模文本即可。那么什么是最接近的呢?自然是每天产生大量内容的社交媒体。
数据
- ACS:基于邮编的纽约市人口普查经济指标
- PLUTO:纽约市房价地价数据。值得感慨的是美国人把这个数据开源到了每栋房屋的级别,坐标、用地类型和价格信息都很详细,数据建设是真的好。考虑到居住人口比移动人口有更好的参考价值,我们根据用地类型筛选出了居住用地,计算了每个邮编区域的平均地价和房价。此外,从ACS数据中选取了最有代表性的中位数收入数据补充到这一组特征中
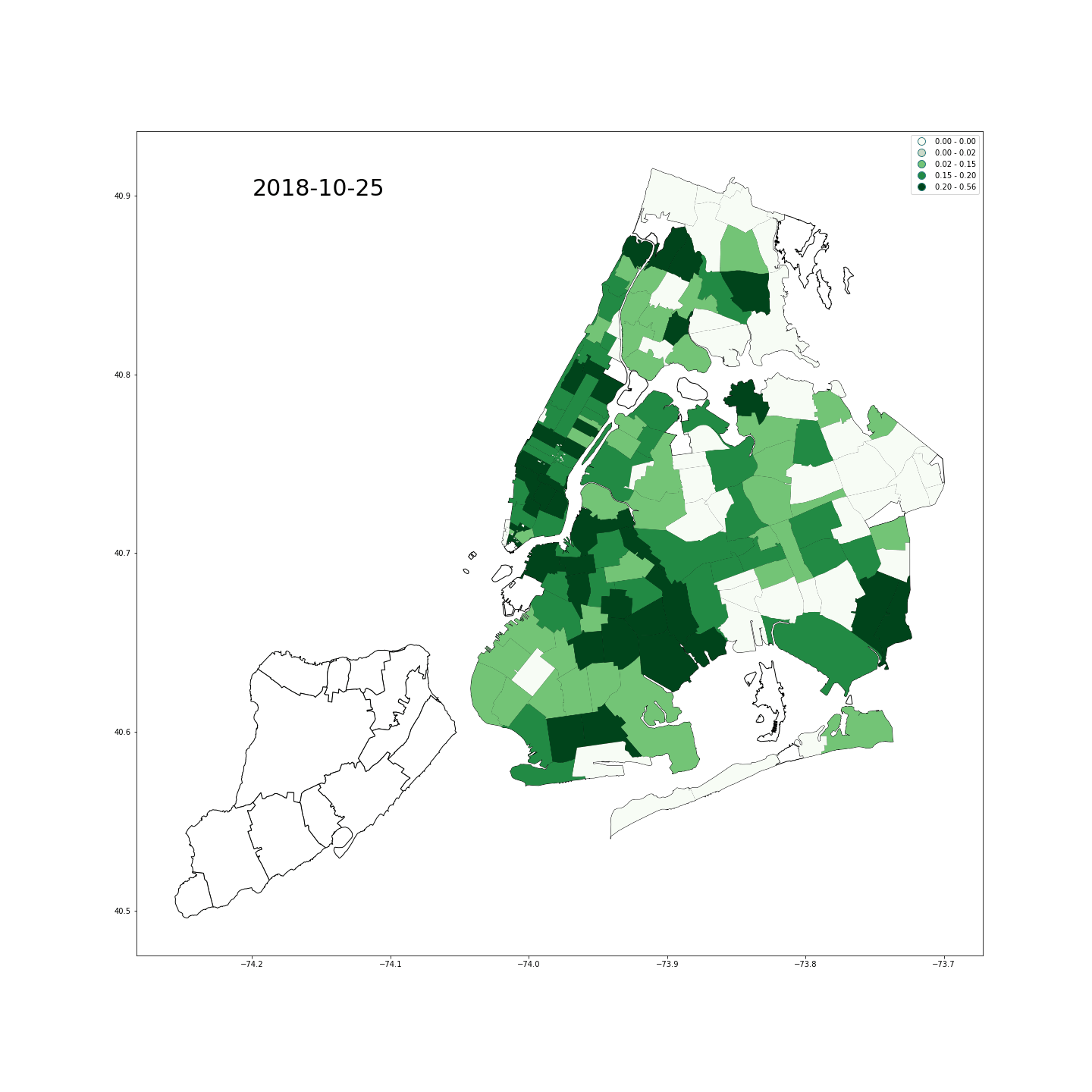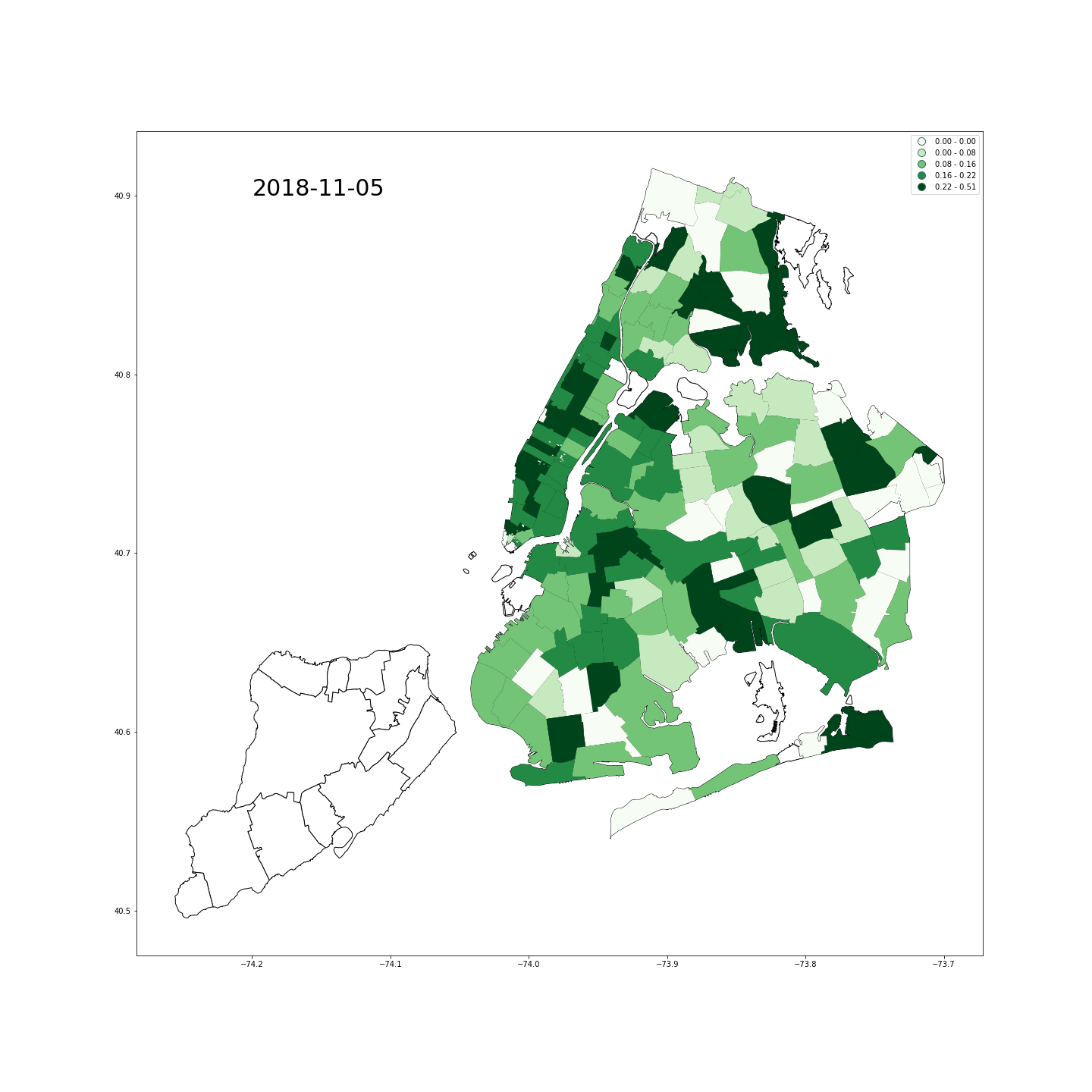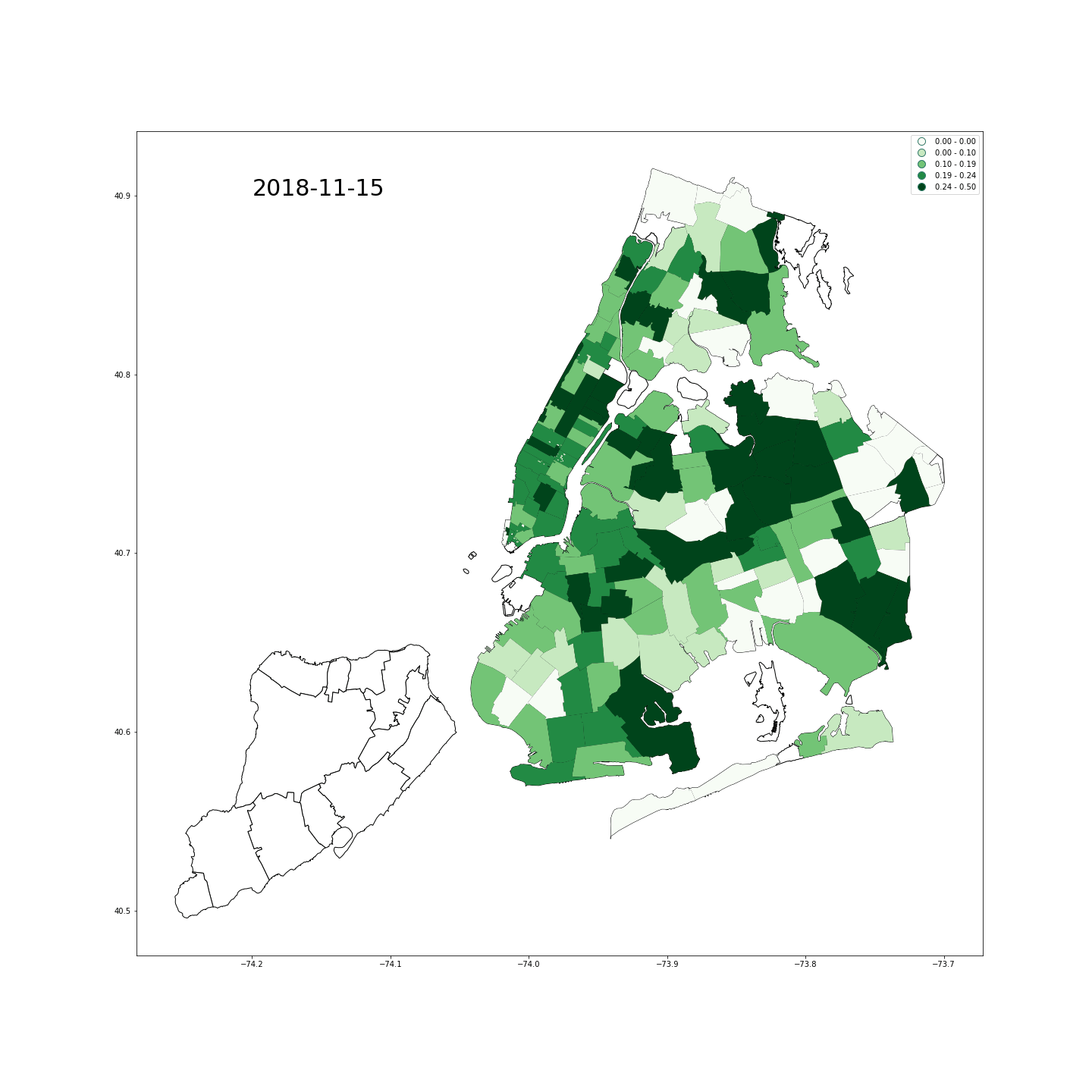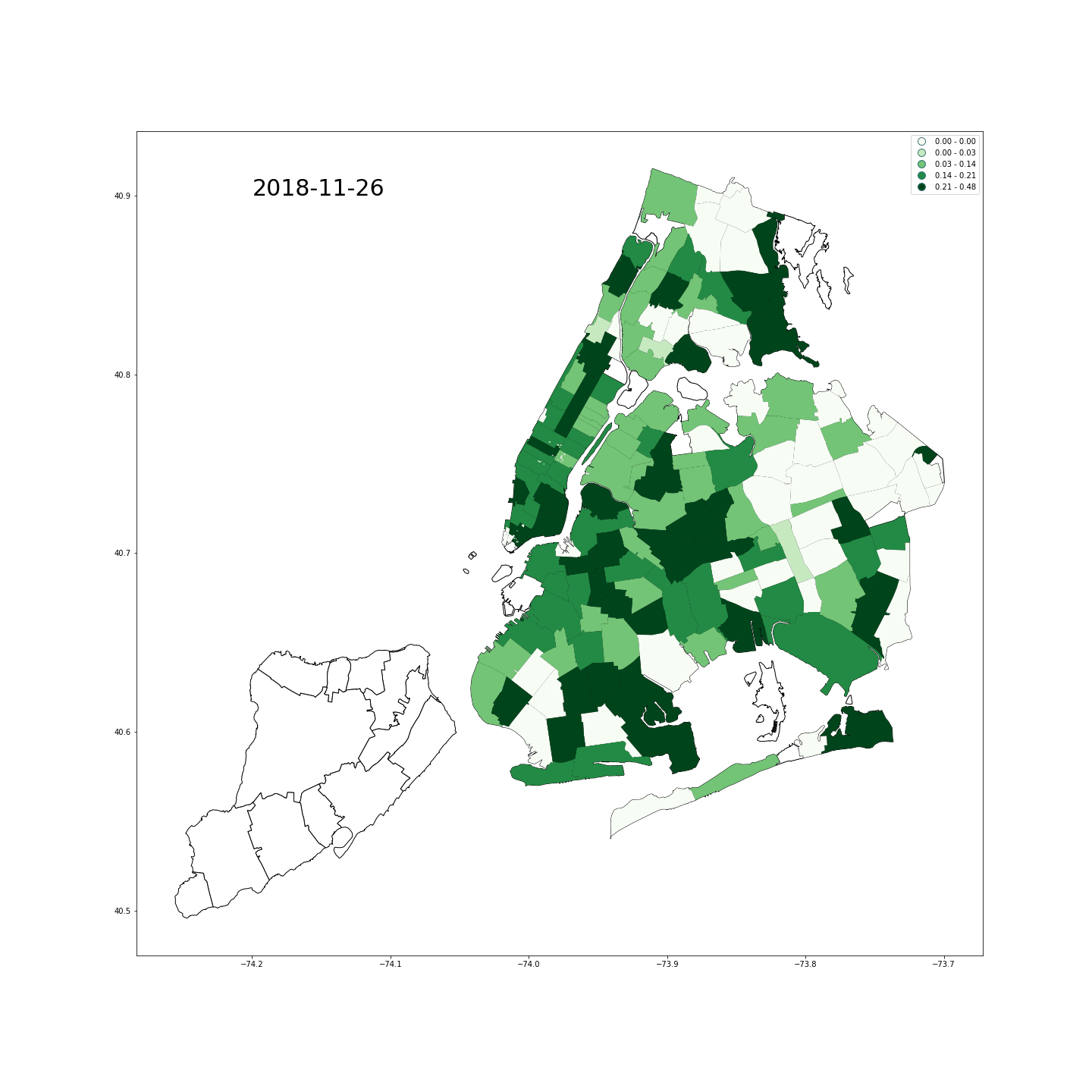
- 情绪:我们使用Twitter API收集了纽约市内从2018年10月24日20点到2018年11月26日19点的带有打卡信息的42万tweets,其中打卡信息就是发推地点的准确经纬度坐标。之后,我们筛选了发送时间在早8点之前和晚7点之后的数据–因为它们更可能来自居住地。紧接着,我们对全部文本进行自然语言处理,包括分词、停用词处理、词形还原和情感分量化等过程。量化时借鉴了两部词典,分别是英文词情感词典和emoji情感词典。至于我们为什么要特别处理emojis,是因为在某些情况下表情符号可以传达文字无法传达的情绪,请看下图:
实验
- 基于以上数据,我们做了相关性检测、回归和分类算法的测试
- 试验结果、代码和非常有趣的诸多GIS图像,请查看本项目
感想
- 第一次自己设计一个有意思的社会学命题,并尝试用数据科学和机器学习的方法去解决问题
- 存在很多问题,特别是人口普查的样本和推特样本严重不一致
- 但还是很自豪,并希望继续努力
- 放一张纽约市积极情绪图做一纪念: