实验室组会分到一篇断言式QA的论文,阅读后总结如下
背景
AAAI 2018
要点
1.定义了基于断言的QA任务(Assertion-based QA)
2.标注了一个Assertion-based QA数据集
3.提出了能够完成Assertion-based QA的两个算法,抽取法和生成法
4.设计了一些实验证明以上方法的效力
内容
定义
- 文章首先介绍了从document_based QA和Assertion_based QA的区别与联系。
- 文章中的断言指的是具有主谓宾、主谓宾补等结构的句子,该句子可能是给定材料的一部分,也可能是新生成的。
数据集
- 由于Assertion-based QA是第一次被提出,所以作者团队标注了一个数据集来做具体的研究(666)。
- 标注方法是先用OIE工具+is-a规则从背景材料中抽取候选断言,然后人工标注断言是否可以作为答案。
算法
第一种算法是生成法。首先用bi-lstm分别对问题和材料编码,拼接尾部隐状态作为特征表示。其次先用一个元组级解码器(Tuple-level decoder)生成结构,然后再用词级别解码器(Word-level Decoder)在结构中逐个生成需要填充的词。下图来自PPT,但是缺了不少信息,我做了批注。
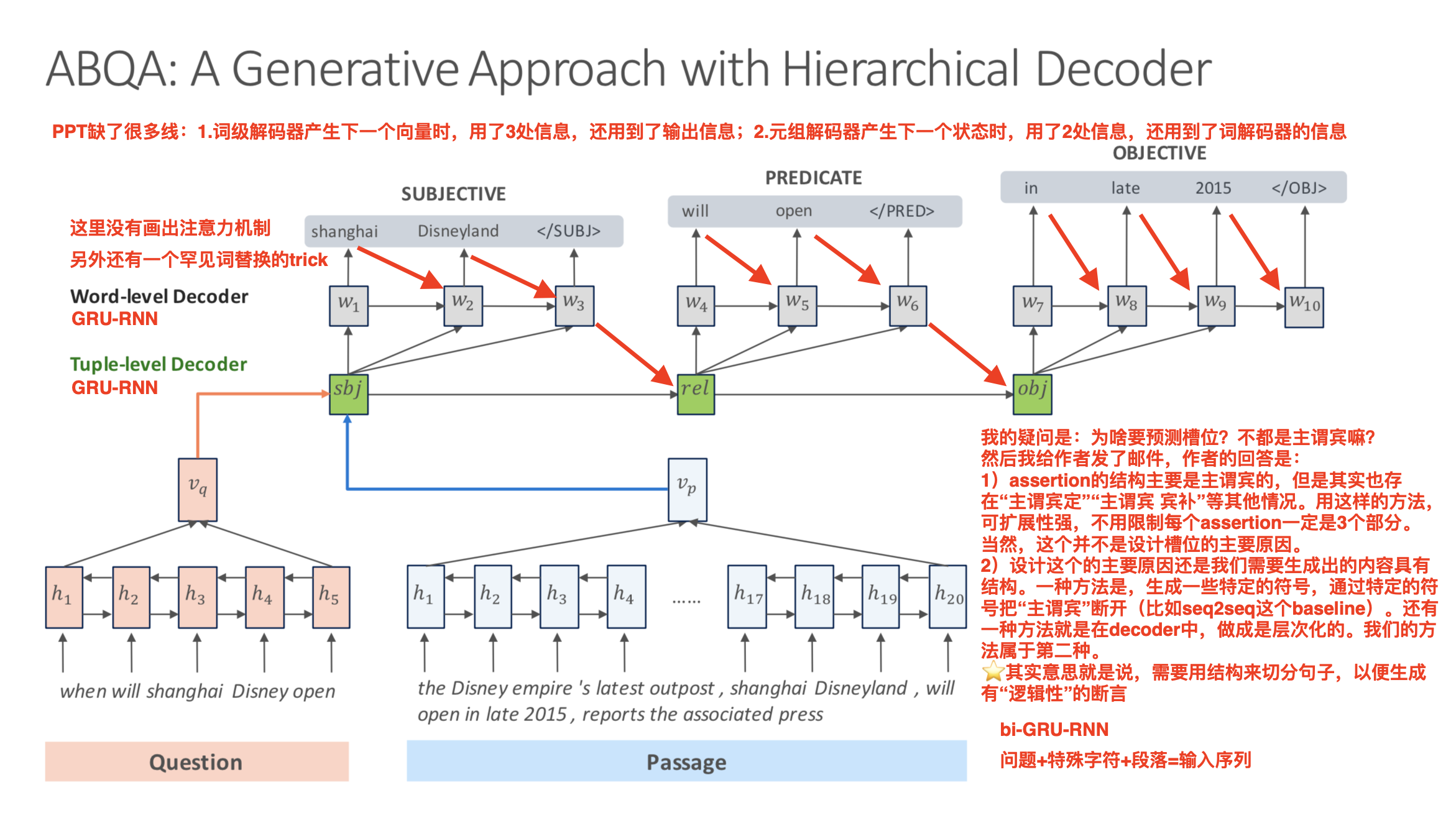
第二种算法是抽取法。抽取法的本质就是对所有候选断言进行机器排序,过程和人工标注很相似。这里的机器排序算法是开源的LambdaMART算法。
需要指出的是,这个方法思路很简单,但是做的比较精致的是特征工程,分别从word、phrase和sentence level抽取了特征进行组合。前两类特征比较简单,sentence level使用了CNN和GRU组合来抽取隐藏层的语义交互特征。下图同样来自PPT,其中包含一些和论文对不上的内容,最后是通过邮件和作者沟通后补充了部分,详情见批注。
实验
- 实验部分文章主要做了4个实验:分别测试生成法和抽取法的效果,以及很创新地分别把生成与抽取的结果再编码成特征放到Passage_based QA中去。后面两个实验是为了证明Assertion_based QA具有更多研究价值,可以辅助别的QA任务。
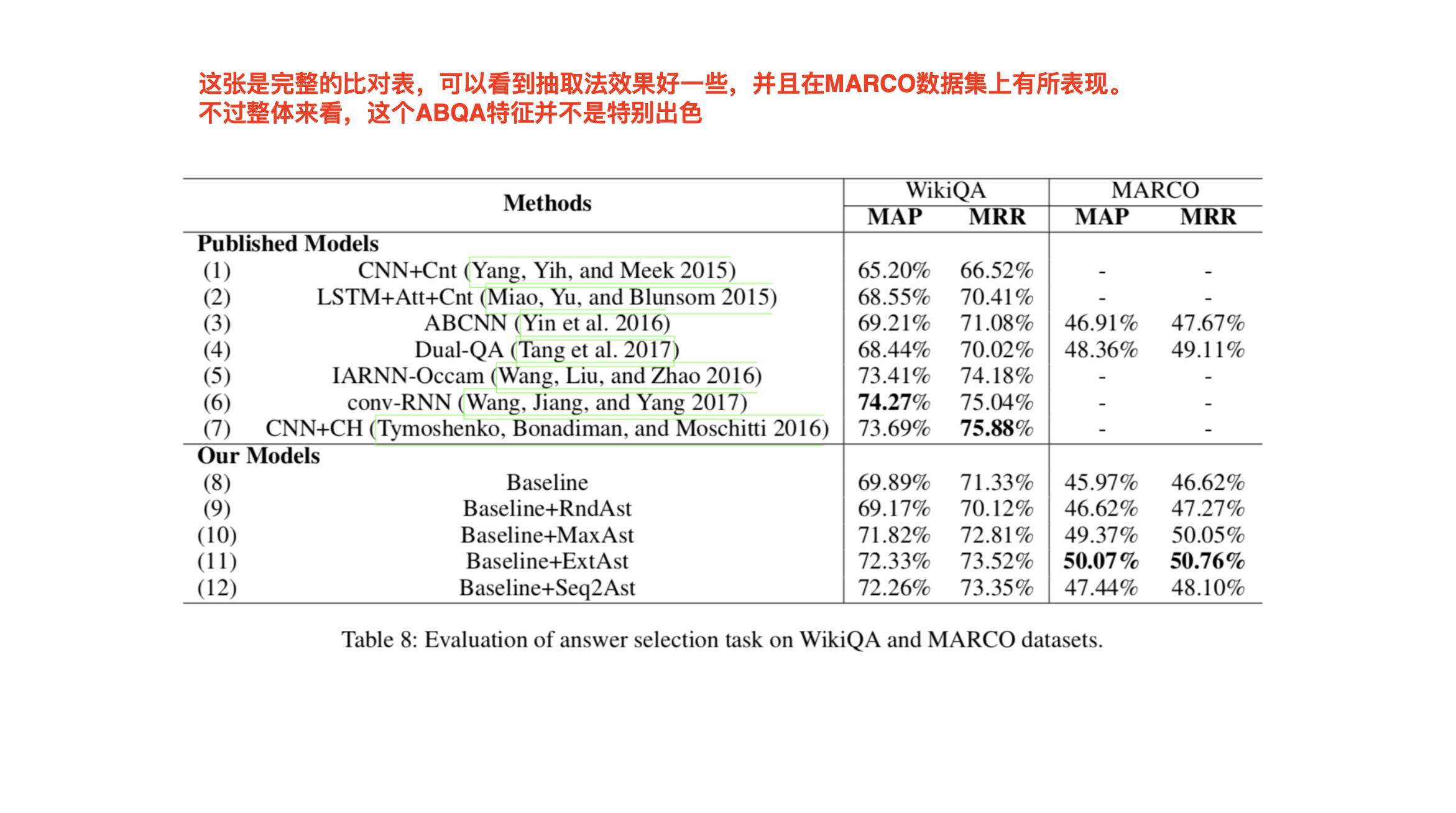
- 不过我感觉PPT有点“王婆卖瓜,自卖自夸”。我从文章中摘了一张针对后两个实验和其它算法一起比较效果的图放在下面,数据显示:1.工程性更重的抽取法效果好于生成法;2.CNN等方法得到的特征效果好于抽取法。
资料
总结
- 总的来说,这篇论文确实做了非常多且较完整的开创性工作,特别是Assertion-based QA的定义和数据集,为QA领域开辟了一些新的思路。尽管提出的算法效果比较一般,但是也可以视作该领域的baseline之一,以鼓励更多更优秀的算法和模型出现。